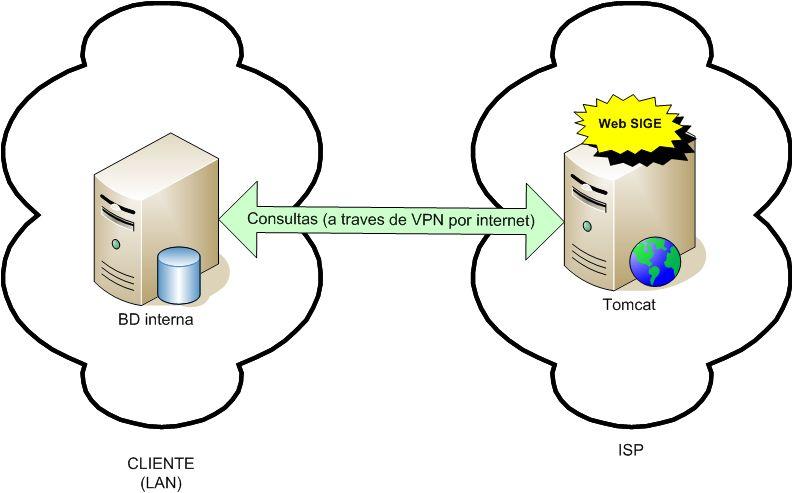
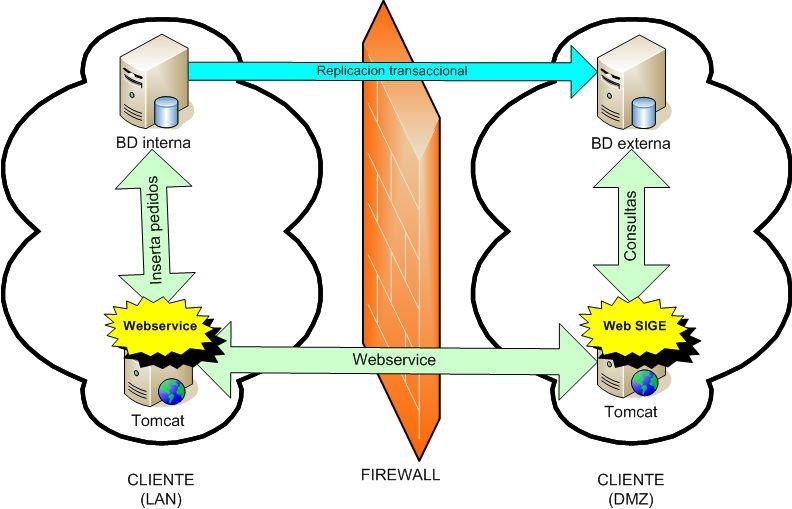
SQL Server al igual que los DBMS’s mas comunes en el mercado utiliza el concepto de esquema para definir un dominio de nombres únicos de objeto.
A modo de ejemplo, en una base SQL Server no es posible tener 2 tablas de nombre “cliente” dentro de un esquema de nombre “sueldos_desarrollo”. Pero si podría tener dentro de la misma base la tabla “cliente” en el esquema “sueldos_desarrollo” y la tabla “cliente” en el esquema “sueldos_testing”.
En SQL Server 2000 el usuario y el esquema están implícitamente relacionados. Al crear un usuario se crea automáticamente un esquema y un esquema no existe sin su usuario asociado.
Este diseño es simple pero tiene algunas desventajas:
- Limita la independencia que deberían tener los desarrolladores para trabajar libremente con los objetos de un esquema y los DBA’s para administrar la seguridad del usuario asociado
- El nombre del esquema puede resultar poco amigable y no refleja la realidad ya que este nombre coincide con el nombre del usuario asociado al esquema.
En SQL Server 2005 este diseño cambia, independizándose el usuario del esquema. Al crear un usuario no se crea un esquema asociado y los esquemas de una base de datos se crean sin asociarse a un usuario.
Este diseño tiene algunas ventajas sobre el anterior:
- Para eliminar un usuario ya no es necesario eliminar previamente todos los objetos del esquema asociado (pues simplemente no hay esquema asociado)
- Se puede renombrar un usuario sin tener que renombrar el esquema, lo cual podía implicar un cambio en las aplicaciones que accedían a tablas de dicho esquema
- Cuando se tenían varios usuarios en una base de datos, al tener cada uno su propio esquema se corría el riesgo de que un usuario creara tablas u otros objetos en su esquema para el caso en que lo deseable fuera concentrar todas las tablas en un único esquema
- El nombre de un esquema no tiene porque coincidir con el nombre de un usuario
Una necesidad que surge de este nuevo diseño es lo que en SQL Server 2005 se llama “esquema por defecto”. Esta propiedad del usuario se usa para determinar la tabla a la que el usuario quiere acceder para el caso en que se haga referencia a un objeto por su nombre sin incluir el esquema como parte del nombre. En el siguiente ejemplo se intenta explicar el funcionamiento de esta propiedad:
Supongamos que en una base se tiene el usuario “supervisor” que tiene como default_schema “sueldos_testing”. Al intentar acceder a la tabla “clientes”, SQL Server 2005 intenta primero ubicarla en el esquema “sueldos_testing”. Si la tabla no existe en ese esquema, SQL Server 2005 intenta como alternativa ubicar la tabla dentro del esquema “dbo”.
Si se estuviera en SQL Server 2000 primero se intentaría ubicar la tabla dentro del esquema “supervisor” (es decir el propio esquema del usuario “supervisor”) y sino se encontrara en este esquema se buscaría en el esquema “dbo”.
Un usuario siempre tiene un esquema por defecto que se indica en la cláusula DEFAULT_SCHEMA de la sentencia CREATE/ALTER USER. Sino se indica un DEFAULT_SCHEMA se asume “dbo” como esquema por defecto.